Reinforcement Learning for Adaptive Resource Management in High-Throughput Satellite Networks
Download Final Report (PDF)Course: SYSC 4700-A — Topics in Communications Networks
Professor: Afsoon Alidadi Shamsabadi
Group Members:
- Samuel Burt
- Colin Byrne
- Earnest George
This project investigates the application of reinforcement learning (RL) techniques to adaptive resource management in high-throughput and very-high-throughput satellite communication systems. The research focuses on how deep reinforcement learning can dynamically optimize bandwidth allocation, power control, routing, and beam scheduling within highly dynamic satellite environments.
The project combines reinforcement learning theory, neural network-based Deep Q-Learning (DQN), and satellite communications research to explore how intelligent agents can improve network efficiency compared to traditional rule-based approaches.
Satellite Communication Systems
Satellite communication systems are commonly categorized by orbital altitude: Low Earth Orbit (LEO), Medium Earth Orbit (MEO), and Geostationary Orbit (GEO). Traditional GEO satellites provide broad coverage areas but are limited in throughput compared to newer multibeam High Throughput Satellite (HTS) architectures.
Modern HTS systems significantly improve total system capacity using frequency reuse and spot-beam technology. Instead of using a single large beam, the coverage area is divided into multiple smaller beams that can reuse frequency bands while minimizing interference.
Very-High Throughput Satellite (VHTS) systems extend this concept even further by increasing beam density and improving spectral efficiency. However, these systems introduce substantial challenges in dynamic resource management due to continuously changing traffic demand, latency constraints, and power limitations.
Because of the complexity of these environments, traditional rule-based resource management techniques are often insufficient for real-time adaptation. This motivates the use of reinforcement learning algorithms capable of learning adaptive control policies directly from interaction with the environment.
Reinforcement Learning Concepts
Reinforcement learning is a machine learning framework where an agent interacts with an environment by observing states, taking actions, and receiving rewards. The goal of the agent is to maximize the cumulative reward over time by learning an optimal policy.
The reinforcement learning framework consists of four major components:
- Policy: The strategy used by the agent to select actions.
- Reward Signal: Feedback from the environment indicating good or bad actions.
- Value Function: An estimate of future long-term rewards.
- Environment Model: A representation of the environment dynamics.
One commonly used exploration strategy is the ε-greedy policy, where the agent occasionally chooses random actions to avoid converging to suboptimal solutions. Initially, exploration is high, but it gradually decreases over time as the agent learns more effective behaviours.
The Bellman Equation forms the mathematical foundation of reinforcement learning by recursively expressing the value of a state in terms of future rewards. This recursive structure enables agents to evaluate long-term consequences instead of only immediate rewards.
Q-Learning extends this concept by estimating the expected reward for specific state-action pairs using a Q-table. The agent continuously updates these values during training based on observed rewards and future state estimates.
Deep Q-Learning and Neural Networks
Traditional Q-Learning suffers from scalability limitations in large state spaces because every possible state-action pair must be stored explicitly within a Q-table. To address this limitation, Deep Q-Networks (DQN) replace the Q-table with a neural network capable of approximating Q-values.
The neural network learns relationships between system states and optimal actions using weighted neuron connections, activation functions, and gradient-based optimization. This allows reinforcement learning agents to operate in significantly more complex environments.
DQN introduces several important improvements over traditional Q-Learning:
- Experience Replay Buffers
- Target Networks
- Mini-batch Gradient Updates
- Improved Training Stability
Experience replay allows previous training experiences to be reused during learning, while target networks stabilize the learning process by updating network weights less frequently. Together, these methods improve convergence and overall learning performance.
During experimentation, reinforcement learning agents were implemented in Python using the Gymnasium framework and trained in benchmark environments such as Taxi-v3 to validate algorithm behaviour before considering more complex satellite communication simulations.
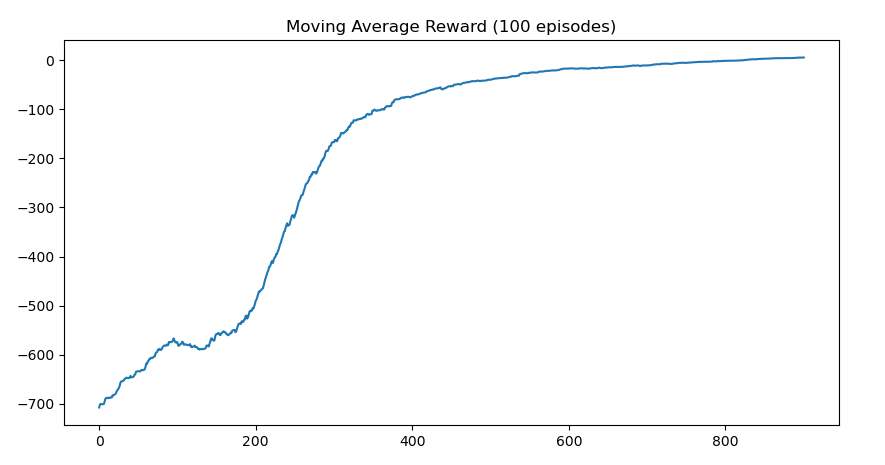
Satellite Resource Management
Resource management in VHTS systems is a highly dynamic optimization problem. Satellite systems must continuously allocate bandwidth, transmission power, beam time, and routing paths while balancing multiple performance metrics simultaneously.
Key performance indicators (KPIs) include:
- Throughput
- Latency
- Power Efficiency
- Fairness
- Quality of Experience (QoE)
Traditional resource management approaches often rely on rule-based scheduling, threshold heuristics, or optimization-based control systems. While effective in stable environments, these methods struggle to adapt to rapidly changing traffic conditions and large-scale multibeam satellite architectures.
Reinforcement learning offers a promising alternative because it can learn adaptive policies directly through interaction with the environment. By modeling satellite resource allocation as a Markov Decision Process (MDP), the agent can optimize long-term system performance rather than only reacting to immediate conditions.
In this formulation, the satellite controller acts as the agent while the environment state may include:
- Beam demand
- Queue lengths
- Round-trip latency
- Available bandwidth
- Power availability
- Satellite-ground geometry
The actions available to the agent include:
- Bandwidth Allocation
- Power Control
- Traffic Steering
- Beam Scheduling
- Routing Decisions
Challenges and Open Research Issues
Although reinforcement learning shows strong potential for satellite communications, several major challenges remain unresolved.
- Nonstationary network conditions
- Large and complex state spaces
- Multi-objective reward balancing
- Scalability limitations
- Simulation-to-real-world deployment challenges
Satellite communication environments are highly dynamic, meaning policies trained under one traffic pattern may not generalize effectively to another. Additionally, reward function design is difficult because improving one performance metric may negatively impact another.
Another major challenge is scalability. Real satellite systems involve continuous variables, extremely large state spaces, and distributed network architectures that are difficult to model efficiently.
Future research must focus on improving generalization, reward stability, and realistic deployment methodologies for reinforcement learning systems in satellite communications.
Proposed System and Novelty
One proposed contribution of this project is the integration of predictive Deep Q-Learning into VHTS systems using target-network forecasting. Instead of reacting only to current network conditions, the reinforcement learning model attempts to estimate future channel-state information (CSI) to improve real-time decision making.
The proposed system would combine reinforcement learning with satellite MIMO communication systems to dynamically adapt routing paths, signal power, beam allocation, and spectrum usage under changing environmental conditions.
The project also explores the use of:
- Multi-Agent Reinforcement Learning (MARL)
- Centralized Training, Decentralized Execution (CTDE)
- Experience Replay for topology adaptation
- FPGA hardware acceleration
- Future Extremely-High Frequency (EHF) satellite systems
In the proposed MARL architecture, each satellite operates as an independent agent while still contributing to a cooperative network-wide optimization objective. This approach improves scalability and robustness in large satellite constellations.
The DQN agent state space includes satellite and ground-station geometry, relative distance, elevation angle, visibility conditions, and network quality metrics such as latency and packet loss.
The reward function is designed to balance multiple communication objectives, including throughput maximization, latency reduction, power efficiency, and link stability.
Future Work
Future development of this project will involve constructing a custom satellite communication simulation environment capable of modeling realistic resource-management scenarios in VHTS systems.
The simulation environment will allow reinforcement learning algorithms to be evaluated under dynamic network conditions involving:
- Dynamic bandwidth allocation
- Beam hopping
- Adaptive routing
- Power optimization
- Satellite topology changes
- Traffic demand variation
Additional future work may also involve implementing reinforcement learning models on FPGA hardware platforms to improve real-time inference performance for large-scale satellite constellations.
The long-term objective of this research is to evaluate whether reinforcement learning can provide scalable, adaptive, and intelligent resource-management solutions for next-generation satellite communication networks.