Reinforcement Learning Experiments
Click a button below to view the corresponding experiment. Only one experiment is visible at a time.
Taxi Using DQN
Environment
The Taxi-v3 environment is a simple grid-world simulation where an agent (the taxi) must pick up and drop off a passenger at a destination. The environment is fully discrete, with defined states and actions:
- States: Represented by the taxi's position, the passenger's location, and the destination.
- Actions: Move north, south, east, west; pick up; drop off.
- Rewards:
- +20 for successfully dropping off the passenger
- -1 per step to encourage efficiency
- -10 for illegal pickup/drop-off actions
The environment is designed to test reinforcement learning algorithms’ ability to learn optimal policies in a small, fully observable world. It emphasizes:
- Planning multiple steps ahead
- Balancing exploration and exploitation
- Learning from sparse and delayed rewards
Here is a visual representation of the grid:

Reference: Gymnasium Taxi Environment
Code
Below is a breakdown of the Deep Q-Learning agent implementation for the Taxi-v3 environment. The code is organized into sections for clarity.
1. Imports and Device Setup
import gymnasium as gym
import numpy as np
import matplotlib.pyplot as plt
from collections import deque
import random
import torch
from torch import nn
import torch.nn.functional as F
import os
# Allow multiple OpenMP instances (sometimes required on Mac)
os.environ["KMP_DUPLICATE_LIB_OK"] = "TRUE"
# Set device to GPU if available
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
This section sets up the Python environment, imports necessary libraries, and configures PyTorch to use GPU if available.
2. Deep Q-Network Definition
class DQN(nn.Module):
def __init__(self, num_states, hidden_size, num_actions):
super().__init__()
self.embedding = nn.Embedding(num_states, 64)
self.fc1 = nn.Linear(64, hidden_size)
self.out = nn.Linear(hidden_size, num_actions)
def forward(self, x):
x = self.embedding(x)
x = F.relu(self.fc1(x))
x = self.out(x)
return x
This neural network estimates the Q-values for each state-action pair. It uses an embedding layer for discrete states, a hidden fully-connected layer, and an output layer for the action values.
3. Replay Memory
class ReplayMemory():
def __init__(self, maxlen):
self.memory = deque([], maxlen=maxlen)
def append(self, transition):
self.memory.append(transition)
def sample(self, sample_size):
return random.sample(self.memory, sample_size)
def __len__(self):
return len(self.memory)
This class stores past experiences for experience replay, which helps stabilize learning by breaking correlations between consecutive steps.
4. Taxi Deep Q-Learning Agent
class TaxiDQL():
learning_rate_a = 0.001
discount_factor_g = 0.99
network_sync_rate = 500
replay_memory_size = 50000
mini_batch_size = 64
def __init__(self):
self.loss_fn = nn.MSELoss()
self.optimizer = None
This class implements the agent that trains and tests the DQN on the Taxi environment, including hyperparameters for learning, discounting, and memory.
5. Training the Agent
def train(self, episodes, render=False):
env = gym.make('Taxi-v3', render_mode='human' if render else None)
...
for episode in range(episodes):
state, _ = env.reset()
...
while not terminated and not truncated:
# Epsilon-greedy action selection
...
# Store experience
memory.append((state, action, new_state, reward, terminated))
...
# Optimize DQN
if len(memory) > self.mini_batch_size and step_count % 4 == 0:
mini_batch = memory.sample(self.mini_batch_size)
self.optimize(mini_batch, policy_dqn, target_dqn)
...
This section contains the main training loop, including the epsilon-greedy policy, storing transitions in memory, and periodically updating the target network.
6. Optimization Step
def optimize(self, mini_batch, policy_dqn, target_dqn):
# Prepare tensors
states = torch.tensor([...])
...
# Compute current Q-values and target Q-values
...
# Compute loss and update network
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
This function performs the gradient descent step to minimize the difference between predicted Q-values and target Q-values from the Bellman equation.
7. Testing the Agent
def test(self, episodes):
env = gym.make('Taxi-v3', render_mode='human')
policy_dqn.load_state_dict(torch.load("taxi_dqn_fast.pt"))
...
while not terminated and not truncated:
# Select best action
...
This section evaluates the trained agent in the Taxi environment, using the policy learned during training.
Code
Full implementation of the Deep Q-Learning agent for the Taxi-v3 environment:
import gymnasium as gym
import numpy as np
import matplotlib.pyplot as plt
from collections import deque
import random
import torch
from torch import nn
import torch.nn.functional as F
import os
os.environ["KMP_DUPLICATE_LIB_OK"] = "TRUE"
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
class DQN(nn.Module):
def __init__(self, num_states, hidden_size, num_actions):
super().__init__()
self.embedding = nn.Embedding(num_states, 64)
self.fc1 = nn.Linear(64, hidden_size)
self.out = nn.Linear(hidden_size, num_actions)
def forward(self, x):
x = self.embedding(x)
x = F.relu(self.fc1(x))
x = self.out(x)
return x
class ReplayMemory():
def __init__(self, maxlen):
self.memory = deque([], maxlen=maxlen)
def append(self, transition):
self.memory.append(transition)
def sample(self, sample_size):
return random.sample(self.memory, sample_size)
def __len__(self):
return len(self.memory)
class TaxiDQL():
learning_rate_a = 0.001
discount_factor_g = 0.99
network_sync_rate = 500
replay_memory_size = 50000
mini_batch_size = 64
def __init__(self):
self.loss_fn = nn.MSELoss()
self.optimizer = None
def train(self, episodes, render=False):
env = gym.make('Taxi-v3', render_mode='human' if render else None)
num_states = env.observation_space.n
num_actions = env.action_space.n
epsilon = 1.0
epsilon_decay = 1 / episodes
epsilon_min = 0.05
memory = ReplayMemory(self.replay_memory_size)
policy_dqn = DQN(num_states, 128, num_actions).to(device)
target_dqn = DQN(num_states, 128, num_actions).to(device)
target_dqn.load_state_dict(policy_dqn.state_dict())
self.optimizer = torch.optim.Adam(policy_dqn.parameters(), lr=self.learning_rate_a)
rewards_per_episode = np.zeros(episodes)
step_count = 0
for episode in range(episodes):
state, _ = env.reset()
terminated = False
truncated = False
episode_reward = 0
while not terminated and not truncated:
if random.random() < epsilon:
action = env.action_space.sample()
else:
with torch.no_grad():
state_tensor = torch.tensor(state, dtype=torch.long, device=device)
action = policy_dqn(state_tensor).argmax().item()
new_state, reward, terminated, truncated, _ = env.step(action)
memory.append((state, action, new_state, reward, terminated))
state = new_state
episode_reward += reward
step_count += 1
if len(memory) > self.mini_batch_size and step_count % 4 == 0:
mini_batch = memory.sample(self.mini_batch_size)
self.optimize(mini_batch, policy_dqn, target_dqn)
if step_count % self.network_sync_rate == 0:
target_dqn.load_state_dict(policy_dqn.state_dict())
rewards_per_episode[episode] = episode_reward
epsilon = max(epsilon - epsilon_decay, epsilon_min)
if episode % 100 == 0:
print(f"Episode {episode} | Reward: {episode_reward} | Epsilon: {epsilon:.3f}")
env.close()
torch.save(policy_dqn.state_dict(), "taxi_dqn_fast.pt")
plt.figure(figsize=(10,5))
moving_avg = np.convolve(rewards_per_episode, np.ones(100)/100, mode='valid')
plt.plot(moving_avg)
plt.title("Moving Average Reward (100 episodes)")
plt.show()
plt.savefig('taxi_dqn')
def optimize(self, mini_batch, policy_dqn, target_dqn):
states = torch.tensor([s for s, _, _, _, _ in mini_batch], dtype=torch.long, device=device)
actions = torch.tensor([a for _, a, _, _, _ in mini_batch], dtype=torch.long, device=device)
next_states = torch.tensor([ns for _, _, ns, _, _ in mini_batch], dtype=torch.long, device=device)
rewards = torch.tensor([r for _, _, _, r, _ in mini_batch], dtype=torch.float32, device=device)
dones = torch.tensor([t for _, _, _, _, t in mini_batch], dtype=torch.float32, device=device)
current_q = policy_dqn(states).gather(1, actions.unsqueeze(1)).squeeze()
with torch.no_grad():
max_next_q = target_dqn(next_states).max(1)[0]
target_q = rewards + (1 - dones) * self.discount_factor_g * max_next_q
loss = self.loss_fn(current_q, target_q)
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
def test(self, episodes):
env = gym.make('Taxi-v3', render_mode='human')
num_states = env.observation_space.n
num_actions = env.action_space.n
policy_dqn = DQN(num_states, 128, num_actions).to(device)
policy_dqn.load_state_dict(torch.load("taxi_dqn_fast.pt", map_location=device))
policy_dqn.eval()
for episode in range(episodes):
state, _ = env.reset()
terminated = False
truncated = False
while not terminated and not truncated:
with torch.no_grad():
state_tensor = torch.tensor(state, dtype=torch.long, device=device)
action = policy_dqn(state_tensor).argmax().item()
state, reward, terminated, truncated, _ = env.step(action)
env.close()
if __name__ == '__main__':
taxi = TaxiDQL()
taxi.train(1000)
taxi.test(5)
Results
The agent was trained for 1000 episodes. Over time, it learned to maximize rewards by efficiently picking up and dropping off passengers.
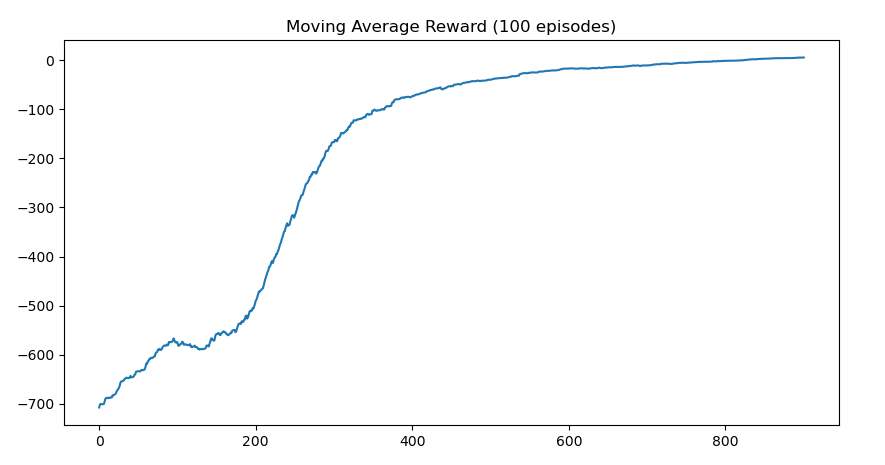
Frozen Lake with DQN
Environment
The FrozenLake-v1 environment is a grid-world where an agent must navigate from the starting point to a goal without falling into holes. It simulates a frozen lake where tiles can be slippery.
- Grid: 4x4 or 8x8 tiles (customizable)
- Goal: Reach the designated goal tile safely
- Holes: Certain tiles end the episode with a negative reward if stepped on
- Reward: +1 for reaching the goal, 0 for each other move, episode ends if agent falls in a hole
- States: The agent’s current position on the grid
- Actions: Move Left, Down, Right, Up
- is_slippery: If set to
True, the agent may slip and end up in a different tile than intended, making the environment stochastic. IfFalse, movements are deterministic.
The FrozenLake environment is often used to test reinforcement learning algorithms in stochastic or deterministic settings depending on the value of is_slippery. It helps illustrate how agents learn to deal with uncertainty in state transitions.
Reference: Gymnasium FrozenLake Environment

Code
Below is a breakdown of the Deep Q-Learning agent implementation for the FrozenLake-v1 environment. The code is organized into sections for clarity.
1. Imports and Device Setup
import gymnasium as gym
import numpy as np
import matplotlib.pyplot as plt
from collections import deque
import pickle
import random
import torch
from torch import nn
import torch.nn.functional as F
import os
os.environ["KMP_DUPLICATE_LIB_OK"]="TRUE"
This section sets up the Python environment, imports necessary libraries, and configures PyTorch to avoid OpenMP conflicts on Mac.
2. Deep Q-Network Definition
class DQN(nn.Module):
def __init__(self, in_states, h1_nodes, out_actions):
super().__init__()
self.fc1 = nn.Linear(in_states, h1_nodes)
self.out = nn.Linear(h1_nodes, out_actions)
def forward(self, x):
x = F.relu(self.fc1(x))
x = self.out(x)
return x
This neural network estimates Q-values for each state-action pair. It uses a fully-connected hidden layer and outputs values for all possible actions.
3. Replay Memory
class ReplayMemory():
def __init__(self, maxlen):
self.memory = deque([], maxlen=maxlen)
def append(self, transition):
self.memory.append(transition)
def sample(self, sample_size):
return random.sample(self.memory, sample_size)
def __len__(self):
return len(self.memory)
This class stores past experiences for experience replay, stabilizing learning by breaking correlations between consecutive steps.
4. FrozenLake Deep Q-Learning Agent
class FrozenLakeDQL():
learning_rate_a = 0.001
discount_factor_g = 0.9
network_sync_rate = 10
replay_memory_size = 1000
mini_batch_size = 32
loss_fn = nn.MSELoss()
optimizer = None
ACTIONS = ['L','D','R','U']
This class implements the agent for the FrozenLake environment, including hyperparameters for learning rate, discount factor, memory size, batch size, and target network synchronization. It also defines the action mapping.
5. Training the Agent
def train(self, episodes, render=False, is_slippery=False):
env = gym.make('FrozenLake-v1', map_name="4x4", is_slippery=is_slippery,
render_mode='human' if render else None)
num_states = env.observation_space.n
num_actions = env.action_space.n
epsilon = 1
memory = ReplayMemory(self.replay_memory_size)
policy_dqn = DQN(in_states=num_states, h1_nodes=num_states, out_actions=num_actions)
target_dqn = DQN(in_states=num_states, h1_nodes=num_states, out_actions=num_actions)
target_dqn.load_state_dict(policy_dqn.state_dict())
self.optimizer = torch.optim.Adam(policy_dqn.parameters(), lr=self.learning_rate_a)
rewards_per_episode = np.zeros(episodes)
epsilon_history = []
step_count = 0
for i in range(episodes):
state = env.reset()[0]
terminated = False
truncated = False
while not terminated and not truncated:
# Epsilon-greedy action selection
...
# Store experience
memory.append((state, action, new_state, reward, terminated))
...
# Optimize DQN if enough memory
if len(memory) > self.mini_batch_size:
mini_batch = memory.sample(self.mini_batch_size)
self.optimize(mini_batch, policy_dqn, target_dqn)
...
This section contains the main training loop, including epsilon-greedy action selection, storing transitions in replay memory, and periodically optimizing the policy network and syncing the target network.
6. Optimization Step
def optimize(self, mini_batch, policy_dqn, target_dqn):
# Compute current Q-values and target Q-values
...
# Compute loss and update network
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
This function performs the gradient descent step to minimize the difference between predicted Q-values and target Q-values computed from the Bellman equation.
7. State to DQN Input
def state_to_dqn_input(self, state:int, num_states:int) -> torch.Tensor:
input_tensor = torch.zeros(num_states)
input_tensor[state] = 1
return input_tensor
Converts a discrete state into a one-hot encoded tensor suitable for the DQN input.
8. Testing the Agent
def test(self, episodes, is_slippery=False):
# Load trained policy and run FrozenLake environment
...
while not terminated and not truncated:
# Select best action
...
This section evaluates the trained agent using the learned policy, navigating the FrozenLake map without exploration.
9. Printing the DQN
def print_dqn(self, dqn):
# Print Q-values and best action for each state
...
This function prints the Q-values and best action for each state in a readable format aligned with the 4x4 FrozenLake map.
Code
Full implementation of the Deep Q-Learning agent for the Frozen Lake-v1 environment:
import gymnasium as gym
import numpy as np
import matplotlib.pyplot as plt
from collections import deque
import pickle
import random
import torch
from torch import nn
import torch.nn.functional as F
import os
os.environ["KMP_DUPLICATE_LIB_OK"]="TRUE"
class DQN(nn.Module):
def __init__(self, in_states, h1_nodes, out_actions):
super().__init__()
self.fc1 = nn.Linear(in_states, h1_nodes)
self.out = nn.Linear(h1_nodes, out_actions)
def forward(self, x):
x = F.relu(self.fc1(x))
x = self.out(x)
return x
class ReplayMemory():
def __init__(self, maxlen):
self.memory = deque([], maxlen=maxlen)
def append(self, transition):
self.memory.append(transition)
def sample(self, sample_size):
return random.sample(self.memory, sample_size)
def __len__(self):
return len(self.memory)
class FrozenLakeDQL():
learning_rate_a = 0.001
discount_factor_g = 0.9
network_sync_rate = 10
replay_memory_size = 1000
mini_batch_size = 32
loss_fn = nn.MSELoss()
optimizer = None
ACTIONS = ['L','D','R','U']
def train(self, episodes, render=False, is_slippery=False):
env = gym.make('FrozenLake-v1', map_name="4x4", is_slippery=is_slippery, render_mode='human' if render else None)
num_states = env.observation_space.n
num_actions = env.action_space.n
epsilon = 1
memory = ReplayMemory(self.replay_memory_size)
policy_dqn = DQN(in_states=num_states, h1_nodes=num_states, out_actions=num_actions)
target_dqn = DQN(in_states=num_states, h1_nodes=num_states, out_actions=num_actions)
target_dqn.load_state_dict(policy_dqn.state_dict())
print('Policy (random, before training):')
self.print_dqn(policy_dqn)
self.optimizer = torch.optim.Adam(policy_dqn.parameters(), lr=self.learning_rate_a)
rewards_per_episode = np.zeros(episodes)
epsilon_history = []
step_count = 0
for i in range(episodes):
print(i)
state = env.reset()[0]
terminated = False
truncated = False
while(not terminated and not truncated):
if random.random() < epsilon:
action = env.action_space.sample()
else:
with torch.no_grad():
action = policy_dqn(self.state_to_dqn_input(state, num_states)).argmax().item()
new_state,reward,terminated,truncated,info = env.step(action)
memory.append((state,action,new_state,reward,terminated))
state = new_state
step_count+=1
if reward==1:
rewards_per_episode[i] = 1
if len(memory)>self.mini_batch_size and np.sum(rewards_per_episode)>0:
mini_batch = memory.sample(self.mini_batch_size)
self.optimize(mini_batch, policy_dqn, target_dqn)
epsilon = max(epsilon - 1/episodes, 0)
epsilon_history.append(epsilon)
if step_count > self.network_sync_rate:
target_dqn.load_state_dict(policy_dqn.state_dict())
step_count=0
env.close()
torch.save(policy_dqn.state_dict(), 'frozen_lake_dqn.pt')
plt.figure(1)
sum_rewards = np.zeros(episodes)
for x in range(episodes):
sum_rewards[x] = np.sum(rewards_per_episode[max(0, x-100):(x+1)])
plt.subplot(121)
plt.plot(sum_rewards)
plt.subplot(122)
plt.plot(epsilon_history)
plt.savefig('frozen_lake_dql')
def optimize(self, mini_batch, policy_dqn, target_dqn):
# Get number of input nodes
num_states = policy_dqn.fc1.in_features
current_q_list = []
target_q_list = []
for state, action, new_state, reward, terminated in mini_batch:
if terminated:
# Agent either reached goal (reward=1) or fell into hole (reward=0)
# When in a terminated state, target q value should be set to the reward.
target = torch.FloatTensor([reward])
else:
# Calculate target q value
with torch.no_grad():
target = torch.FloatTensor(
reward + self.discount_factor_g * target_dqn(self.state_to_dqn_input(new_state, num_states)).max()
)
# Get the current set of Q values
current_q = policy_dqn(self.state_to_dqn_input(state, num_states))
current_q_list.append(current_q)
# Get the target set of Q values
target_q = target_dqn(self.state_to_dqn_input(state, num_states))
# Adjust the specific action to the target that was just calculated
target_q[action] = target
target_q_list.append(target_q)
# Compute loss for the whole minibatch
loss = self.loss_fn(torch.stack(current_q_list), torch.stack(target_q_list))
# Optimize the model
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
def state_to_dqn_input(self, state:int, num_states:int)->torch.Tensor:
input_tensor = torch.zeros(num_states)
input_tensor[state] = 1
return input_tensor
# Run the FrozeLake environment with the learned policy
def test(self, episodes, is_slippery=False):
# Create FrozenLake instance
env = gym.make('FrozenLake-v1', map_name="4x4", is_slippery=is_slippery, render_mode='human')
num_states = env.observation_space.n
num_actions = env.action_space.n
# Load learned policy
policy_dqn = DQN(in_states=num_states, h1_nodes=num_states, out_actions=num_actions)
policy_dqn.load_state_dict(torch.load("frozen_lake_dqn.pt"))
policy_dqn.eval() # switch model to evaluation mode
print('Policy (trained):')
self.print_dqn(policy_dqn)
for i in range(episodes):
state = env.reset()[0] # Initialize to state 0
terminated = False # True when agent falls in hole or reached goal
truncated = False # True when agent takes more than 200 actions
# Agent navigates map until it falls into a hole (terminated), reaches goal (terminated), or has taken 200 actions (truncated).
while(not terminated and not truncated):
# Select best action
with torch.no_grad():
action = policy_dqn(self.state_to_dqn_input(state, num_states)).argmax().item()
# Execute action
state,reward,terminated,truncated,_ = env.step(action)
env.close()
# Print DQN: state, best action, q values
def print_dqn(self, dqn):
# Get number of input nodes
num_states = dqn.fc1.in_features
# Loop each state and print policy to console
for s in range(num_states):
# Format q values for printing
q_values = ''
for q in dqn(self.state_to_dqn_input(s, num_states)).tolist():
q_values += "{:+.2f}".format(q)+' ' # Concatenate q values, format to 2 decimals
q_values=q_values.rstrip() # Remove space at the end
# Map the best action to L D R U
best_action = self.ACTIONS[dqn(self.state_to_dqn_input(s, num_states)).argmax()]
# Print policy in the format of: state, action, q values
# The printed layout matches the FrozenLake map.
print(f'{s:02},{best_action},[{q_values}]', end=' ')
if (s+1)%4==0:
print() # Print a newline every 4 states
if __name__ == '__main__':
frozen_lake = FrozenLakeDQL()
is_slippery = True
frozen_lake.train(5000, is_slippery=is_slippery)
frozen_lake.test(10, is_slippery=is_slippery)
Results
This section shows the training results for the Frozen Lake DQN agent on the 4x4 grid. Two cases are shown: deterministic movement (is_slippery=False) and stochastic movement (is_slippery=True).
1. Frozen Lake (Deterministic, is_slippery=False)
In this case, the agent's movements are deterministic, meaning each action always succeeds as intended. The following plot shows:
- Left graph: Sum of rewards per 100 episodes
- Right graph: Epsilon value decay over training
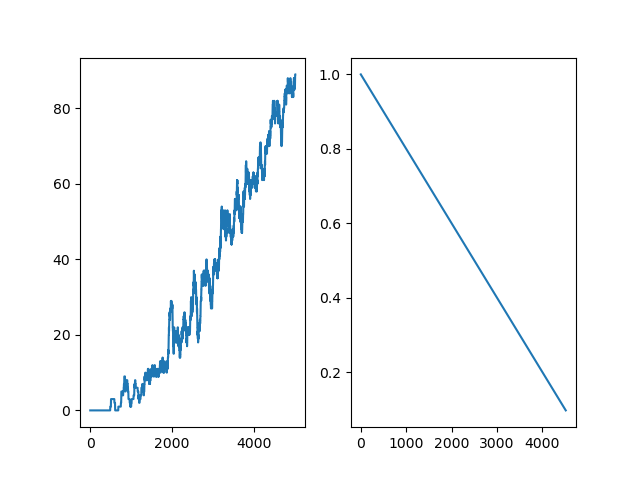
2. Frozen Lake (Stochastic, is_slippery=True)
Here, the lake is slippery, so each action may not always go as intended. This introduces more uncertainty and requires the agent to learn a robust policy. The plot again shows:
- Left graph: Sum of rewards per 100 episodes
- Right graph: Epsilon value decay over training
Frozen Lake with CNN
Environment
The FrozenLake-v1 environment is a grid-world where an agent must navigate from the starting point to a goal without falling into holes. It simulates a frozen lake where tiles can be slippery.
- Grid: 4x4 or 8x8 tiles (customizable)
- Goal: Reach the designated goal tile safely
- Holes: Certain tiles end the episode with a negative reward if stepped on
- Reward: +1 for reaching the goal, 0 for each other move, episode ends if agent falls in a hole
- States: The agent’s current position on the grid
- Actions: Move Left, Down, Right, Up
- is_slippery: If set to
True, the agent may slip and end up in a different tile than intended, making the environment stochastic. IfFalse, movements are deterministic.
The FrozenLake environment is often used to test reinforcement learning algorithms in stochastic or deterministic settings depending on the value of is_slippery. It helps illustrate how agents learn to deal with uncertainty in state transitions.
Reference: Gymnasium FrozenLake Environment
Code
Below is a breakdown of the Convolutional Deep Q-Learning agent for the Frozen Lake 4x4 environment. The code is organized into sections for clarity.
1. Imports and Setup
import gymnasium as gym
import numpy as np
import matplotlib.pyplot as plt
from collections import deque
import random
import torch
from torch import nn
import torch.nn.functional as F
import math
import os
# Allow multiple OpenMP instances (sometimes required)
os.environ["KMP_DUPLICATE_LIB_OK"] = "TRUE"
This section imports necessary libraries and sets up the Python environment for deep reinforcement learning.
2. Convolutional Deep Q-Network Definition
class DQN(nn.Module):
def __init__(self, input_channels, num_actions):
super().__init__()
self.conv_block1 = nn.Sequential(
nn.Conv2d(input_channels, 10, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.Conv2d(10, 10, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.MaxPool2d(2)
)
self.conv_block2 = nn.Sequential(
nn.Conv2d(10, 10, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.Conv2d(10, 10, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.MaxPool2d(2)
)
self.output_layer = nn.Sequential(
nn.Flatten(),
nn.Linear(10*1*1, num_actions)
)
def forward(self, x):
x = self.conv_block1(x)
x = self.conv_block2(x)
return self.output_layer(x)
This network takes a 4x4 map as input (3 channels for RGB encoding), passes it through two convolutional blocks with pooling, then flattens it and outputs Q-values for each action.
3. Replay Memory
class ReplayMemory:
def __init__(self, max_size):
self.memory = deque(maxlen=max_size)
def append(self, transition):
self.memory.append(transition)
def sample(self, batch_size):
return random.sample(self.memory, batch_size)
def __len__(self):
return len(self.memory)
This class stores past experiences for experience replay to stabilize training by reducing correlations between consecutive steps.
4. CNN-based Frozen Lake Deep Q-Learning Agent
class FrozenLakeDQL:
alpha = 0.001
gamma = 0.9
sync_steps = 10
memory_size = 1000
batch_size = 32
ACTIONS = ['L','D','R','U']
def __init__(self):
self.loss_fn = nn.MSELoss()
self.optimizer = None
Defines the agent class with learning parameters, memory size, discount factor, and the four actions for Frozen Lake.
5. State to Tensor Conversion
def state_to_tensor(self, state: int) -> torch.Tensor:
tensor = torch.zeros(1, 3, 4, 4)
row, col = divmod(state, 4)
tensor[0, 0, row, col] = 245 / 255 # Red channel
tensor[0, 1, row, col] = 66 / 255 # Green channel
tensor[0, 2, row, col] = 120 / 255 # Blue channel
return tensor
This method encodes a single state as a 3-channel 4x4 tensor for the CNN input.
6. Optimization Step
def optimize(self, batch, policy_net, target_net):
current_qs, target_qs = [], []
for state, action, next_state, reward, done in batch:
target = torch.FloatTensor([reward]) if done else \
torch.FloatTensor([reward + self.gamma * target_net(self.state_to_tensor(next_state)).max()])
current_q = policy_net(self.state_to_tensor(state))
target_q = target_net(self.state_to_tensor(state))
target_q[0, action] = target
current_qs.append(current_q)
target_qs.append(target_q)
loss = self.loss_fn(torch.stack(current_qs), torch.stack(target_qs))
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
Updates the policy network using the Bellman equation for Q-values with a batch of experiences.
7. Training Loop
def train(self, episodes, render=False, is_slippery=False):
env = gym.make('FrozenLake-v1', map_name="4x4",
is_slippery=is_slippery,
render_mode='human' if render else None)
num_actions = env.action_space.n
epsilon = 1.0
memory = ReplayMemory(self.memory_size)
policy_net = DQN(3, num_actions)
target_net = DQN(3, num_actions)
target_net.load_state_dict(policy_net.state_dict())
self.optimizer = torch.optim.Adam(policy_net.parameters(), lr=self.alpha)
rewards_history = np.zeros(episodes)
epsilon_history = []
step_count = 0
for ep in range(episodes):
state, terminated, truncated = env.reset()[0], False, False
while not terminated and not truncated:
action = env.action_space.sample() if random.random() < epsilon \
else policy_net(self.state_to_tensor(state)).argmax().item()
next_state, reward, terminated, truncated, _ = env.step(action)
memory.append((state, action, next_state, reward, terminated))
state = next_state
step_count += 1
rewards_history[ep] = reward
if len(memory) > self.batch_size and rewards_history.sum() > 0:
batch = memory.sample(self.batch_size)
self.optimize(batch, policy_net, target_net)
epsilon = max(epsilon - 1/episodes, 0)
epsilon_history.append(epsilon)
if step_count > self.sync_steps:
target_net.load_state_dict(policy_net.state_dict())
step_count = 0
env.close()
torch.save(policy_net.state_dict(), "frozen_lake_dql_cnn.pt")
Main training loop: epsilon-greedy action selection, experience storage, network optimization, and periodic target network updates.
8. Testing the Trained Policy
def test(self, episodes, is_slippery=False):
env = gym.make('FrozenLake-v1', map_name="4x4",
is_slippery=is_slippery, render_mode='human')
num_actions = env.action_space.n
policy_net = DQN(3, num_actions)
policy_net.load_state_dict(torch.load("frozen_lake_dql_cnn.pt"))
policy_net.eval()
for _ in range(episodes):
state, terminated, truncated = env.reset()[0], False, False
while not terminated and not truncated:
with torch.no_grad():
action = policy_net(self.state_to_tensor(state)).argmax().item()
state, _, terminated, truncated, _ = env.step(action)
env.close()
This evaluates the trained CNN agent in the Frozen Lake environment for a given number of episodes.
9. Displaying Learned Policy
def print_policy(self, net):
for s in range(16):
q_vals = net(self.state_to_tensor(s))[0].tolist()
best_action = self.ACTIONS[torch.tensor(q_vals).argmax()]
formatted_qs = ' '.join(f"{q:+.2f}" for q in q_vals)
print(f"{s:02},{best_action},[{formatted_qs}]", end=' ')
if (s + 1) % 4 == 0:
print()
Prints the Q-values and best action for each state in the 4x4 grid, row by row.
Code
Full implementation of the CNN agent for the Frozenlake-v1 environment:
import gymnasium as gym
import numpy as np
import matplotlib.pyplot as plt
from collections import deque
import random
import torch
from torch import nn
import torch.nn.functional as F
import math
import os
os.environ["KMP_DUPLICATE_LIB_OK"] = "TRUE"
class DQN(nn.Module):
def __init__(self, input_channels, num_actions):
super().__init__()
self.conv_block1 = nn.Sequential(
nn.Conv2d(input_channels, 10, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.Conv2d(10, 10, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.MaxPool2d(2)
)
self.conv_block2 = nn.Sequential(
nn.Conv2d(10, 10, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.Conv2d(10, 10, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.MaxPool2d(2)
)
# After flattening, input size is 10*1*1 for 4x4 map
self.output_layer = nn.Sequential(
nn.Flatten(),
nn.Linear(10 * 1 * 1, num_actions)
)
def forward(self, x):
x = self.conv_block1(x)
x = self.conv_block2(x)
return self.output_layer(x)
class ReplayMemory:
def __init__(self, max_size):
self.memory = deque(maxlen=max_size)
def append(self, transition):
self.memory.append(transition)
def sample(self, batch_size):
return random.sample(self.memory, batch_size)
def __len__(self):
return len(self.memory)
class FrozenLakeDQL:
# Hyperparameters
alpha = 0.001
gamma = 0.9
sync_steps = 10
memory_size = 1000
batch_size = 32
ACTIONS = ['L', 'D', 'R', 'U']
def __init__(self):
self.loss_fn = nn.MSELoss()
self.optimizer = None
# Convert state to DQN input tensor
def state_to_tensor(self, state: int) -> torch.Tensor:
tensor = torch.zeros(1, 3, 4, 4)
row, col = divmod(state, 4)
tensor[0, 0, row, col] = 245 / 255
tensor[0, 1, row, col] = 66 / 255
tensor[0, 2, row, col] = 120 / 255
return tensor
# Optimize policy network
def optimize(self, batch, policy_net, target_net):
current_qs, target_qs = [], []
for state, action, next_state, reward, done in batch:
target = torch.FloatTensor([reward]) if done else \
torch.FloatTensor([reward + self.gamma * target_net(self.state_to_tensor(next_state)).max()])
current_q = policy_net(self.state_to_tensor(state))
target_q = target_net(self.state_to_tensor(state))
target_q[0, action] = target
current_qs.append(current_q)
target_qs.append(target_q)
loss = self.loss_fn(torch.stack(current_qs), torch.stack(target_qs))
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
# Train the agent
def train(self, episodes, render=False, is_slippery=False):
env = gym.make('FrozenLake-v1', map_name="4x4",
is_slippery=is_slippery,
render_mode='human' if render else None)
num_states = env.observation_space.n
num_actions = env.action_space.n
epsilon = 1.0
memory = ReplayMemory(self.memory_size)
policy_net = DQN(input_channels=3, num_actions=num_actions)
target_net = DQN(input_channels=3, num_actions=num_actions)
target_net.load_state_dict(policy_net.state_dict())
self.optimizer = torch.optim.Adam(policy_net.parameters(), lr=self.alpha)
rewards_history = np.zeros(episodes)
epsilon_history = []
step_count = 0
print('Policy (before training):')
self.print_policy(policy_net)
for ep in range(episodes):
state, terminated, truncated = env.reset()[0], False, False
while not terminated and not truncated:
action = env.action_space.sample() if random.random() < epsilon \
else policy_net(self.state_to_tensor(state)).argmax().item()
next_state, reward, terminated, truncated, _ = env.step(action)
memory.append((state, action, next_state, reward, terminated))
state = next_state
step_count += 1
rewards_history[ep] = reward
if len(memory) > self.batch_size and rewards_history.sum() > 0:
batch = memory.sample(self.batch_size)
self.optimize(batch, policy_net, target_net)
epsilon = max(epsilon - 1 / episodes, 0)
epsilon_history.append(epsilon)
if step_count > self.sync_steps:
target_net.load_state_dict(policy_net.state_dict())
step_count = 0
env.close()
torch.save(policy_net.state_dict(), "frozen_lake_dql_cnn.pt")
# Plot rewards and epsilon
plt.figure(figsize=(10, 4))
rolling_rewards = [np.sum(rewards_history[max(0, i - 100):(i + 1)]) for i in range(episodes)]
plt.subplot(1, 2, 1)
plt.plot(rolling_rewards)
plt.title('Rolling Rewards')
plt.subplot(1, 2, 2)
plt.plot(epsilon_history)
plt.title('Epsilon Decay')
plt.savefig('frozen_lake_dql_cnn.png')
# Test learned policy
def test(self, episodes, is_slippery=False):
env = gym.make('FrozenLake-v1', map_name="4x4", is_slippery=is_slippery, render_mode='human')
num_actions = env.action_space.n
policy_net = DQN(input_channels=3, num_actions=num_actions)
policy_net.load_state_dict(torch.load("frozen_lake_dql_cnn.pt"))
policy_net.eval()
print('Policy (trained):')
self.print_policy(policy_net)
for _ in range(episodes):
state, terminated, truncated = env.reset()[0], False, False
while not terminated and not truncated:
with torch.no_grad():
action = policy_net(self.state_to_tensor(state)).argmax().item()
state, _, terminated, truncated, _ = env.step(action)
env.close()
# Print the Q-values and best action for each state
def print_policy(self, net):
for s in range(16):
q_vals = net(self.state_to_tensor(s))[0].tolist()
best_action = self.ACTIONS[torch.tensor(q_vals).argmax()]
formatted_qs = ' '.join(f"{q:+.2f}" for q in q_vals)
print(f"{s:02},{best_action},[{formatted_qs}]", end=' ')
if (s + 1) % 4 == 0:
print()
if __name__ == "__main__":
agent = FrozenLakeDQL()
slippery = False
agent.train(1000, is_slippery=slippery)
agent.test(10, is_slippery=slippery)
Results
This section shows the training results for the Frozen Lake CNN agent on the 4x4 grid. Two cases are shown: deterministic movement (is_slippery=False) and stochastic movement (is_slippery=True).
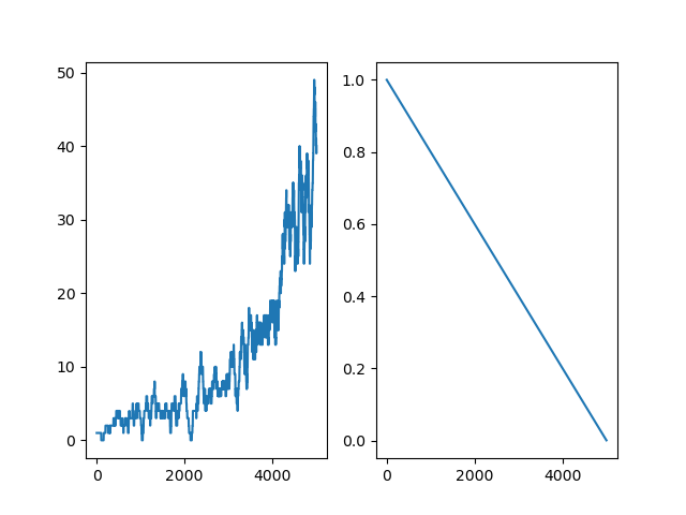
1. Frozen Lake (Deterministic, is_slippery=False)
In this case, the agent's movements are deterministic, meaning each action always succeeds as intended. The following plot shows:
- Left graph: Rolling rewards
- Right graph: Epsilon value decay over training
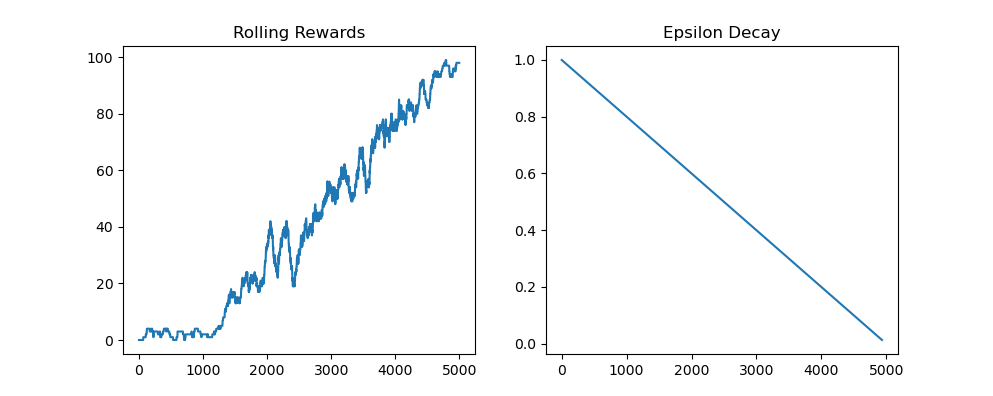
2. Frozen Lake (Stochastic, is_slippery=True)
Here, the lake is slippery, so each action may not always go as intended. This introduces more uncertainty and requires the agent to learn a robust policy. The plot again shows:
- Left graph: Rolling rewards
- Right graph: Epsilon value decay over training
Custom Golf Environment with DQN Agent
Environment
The Golf-v0 environment is a simplified golf simulation where an agent must learn how to reach the hole using different golf clubs. The environment models a one-dimensional fairway where the agent repeatedly selects a club to hit the ball toward the hole. The goal is to minimize the remaining distance while reaching the hole within a limited number of strokes.
- States: The observation consists of the remaining distance to the hole (in yards). This value changes after each shot depending on the club used and the randomness of the shot.
- Actions: The agent chooses one of six clubs:
- Putter (forward)
- Iron (forward)
- Driver (forward)
- Putter (backward)
- Iron (backward)
- Driver (backward)
- Rewards:
- +10 for successfully landing the ball in the hole
- A negative reward proportional to the remaining distance after each shot
- A large penalty if the agent exceeds the maximum allowed number of strokes
The environment is inspired by the golf example discussed in the finite Markov Decision Processes section of reinforcement learning literature. In this simplified version, the golf course is represented as a single straight line rather than a full 2D course.
- The ball begins far from the hole (e.g., ~400 yards)
- The agent must select appropriate clubs to reduce the distance efficiently
- Different difficulty settings introduce randomness in shot distances
- The episode ends when the ball reaches the hole or the stroke limit is exceeded
This environment helps demonstrate reinforcement learning concepts such as:
- Sequential decision making under uncertainty
- Learning optimal action choices based on distance
- Balancing aggressive and conservative strategies
Here is a visual representation of the environment:

Reference: Inspired by the golf reinforcement learning example described in the Sutton & Barto reinforcement learning textbook.
Code
Below is a breakdown of the custom Golf-v0 reinforcement learning environment. The code defines a one-dimensional golf simulation where an agent selects clubs to move a ball toward a hole. The implementation follows the Gymnasium environment interface.
1. Imports and Environment Registration
import gymnasium as gym
from gymnasium import spaces
from gymnasium.envs.registration import register
from enum import Enum
import numpy as np
import pygame
register(
id='golf-v0',
entry_point='golf_game:GolfEnv',
)
This section imports required libraries. The environment is then registered with Gymnasium so it can be created using gym.make("golf-v0"). The entry_point tells Gymnasium which class implements the environment.
2. Custom Environment Class
class GolfEnv(gym.Env):
metadata = {'render_modes': ['human']}
This class defines the custom reinforcement learning environment. It inherits from gym.Env and follows Gymnasium’s standard interface: reset(), step(), and render().
3. Environment Initialization
def __init__(self, render_mode=None, difficulty='Easy'):
self.render_mode = render_mode
self.clock = None
self.fps = 1
self.hole_radius = 25.0
self.max_distance = 500
self.start_distance = 400
self.num_strokes = 0
The constructor initializes environment parameters such as the maximum distance of the course, the starting distance from the hole, and the number of strokes taken. Rendering parameters such as frame rate and display settings are also defined here.
4. Club Distance Models
if(difficulty=='Easy'):
self.clubs = {
0: (10, 0),
1: (50, 0),
2: (200, 0),
3: (10, 0),
4: (50, 0),
5: (200, 0)
}
Each action corresponds to a golf club defined by a mean distance and standard deviation. The standard deviation introduces randomness in the shot distance.
Three difficulty levels are supported:
- Easy: Deterministic shots (no randomness)
- Medium: Moderate randomness
- Hard: Large variability in shot distance
5. Action and Observation Spaces
self.action_space = spaces.Discrete(len(self.clubs))
self.observation_space = spaces.Box(
low=0,
high=self.max_distance,
shape=(1,),
dtype=np.float32
)
The action space consists of six discrete actions representing different golf clubs and directions. The observation space contains a single continuous value: the remaining distance to the hole.
6. Reset Function
def reset(self, seed=None, options=None):
super().reset(seed=seed)
self.distance = self.start_distance
self.ball_position = self.max_distance - self.distance
self.num_strokes = 0
self.total_reward = 0
observation = np.array([self.distance], dtype=np.float32)
info = {}
return observation, info
The reset() method initializes the environment at the start of an episode. The ball begins a fixed distance from the hole, stroke counters are reset, and the initial observation (distance to the hole) is returned.
7. Step Function (Environment Dynamics)
def step(self, action):
mean, std = self.clubs[action]
shot = self.np_random.normal(mean, std)
if(action < 3):
self.distance -= shot
else:
self.distance += shot
The step() function updates the environment after the agent selects an action. A shot distance is sampled from a normal distribution based on the selected club. Forward clubs reduce the remaining distance to the hole, while backward clubs increase it.
8. Rewards and Episode Termination
terminated = abs(self.distance) <= self.hole_radius
truncated = self.num_strokes > 10
if terminated:
reward = 10
elif truncated:
reward = -10000
else:
reward = -abs(self.distance)/100
The reward structure encourages the agent to reach the hole efficiently:
- +10 reward for successfully reaching the hole
- Negative reward proportional to remaining distance
- Large penalty if the maximum number of strokes is exceeded
9. Rendering the Environment
pygame.draw.circle(canvas, (0, 0, 0), (hole_x, 100), 6)
progress = (self.max_distance - self.distance) / self.max_distance
ball_x = int(progress * (self.window_size - 100)) + 50
pygame.draw.circle(canvas, (255, 255, 255), (ball_x, 100), 8)
The render() method visualizes the environment using Pygame. The hole is drawn as a black circle, while the ball position is calculated based on the remaining distance and displayed as a white circle moving across the screen.
10. Environment Validation
def check_env():
from gymnasium.utils.env_checker import check_env
env = gym.make('golf-v0', render_mode='human')
check_env(env.unwrapped)
This function verifies that the environment follows Gymnasium’s API conventions using the built-in environment checker.
11. Random Policy Rollout
def random_rollout():
env = gym.make("golf-v0")
obs, _ = env.reset()
done = False
while not done:
action = env.action_space.sample()
obs, reward, terminated, truncated, info = env.step(action)
done = terminated or truncated
This function runs a simple simulation where actions are chosen randomly. It demonstrates how the environment behaves and allows basic testing before applying reinforcement learning algorithms.
12. Running the Script
if __name__ == "__main__":
check_env()
random_rollout()
When the script is executed directly, the environment is first validated and then tested using a random policy rollout.
Environment Full Code
Full implementation of the Golf environment
import gymnasium as gym
from gymnasium import spaces
from gymnasium.envs.registration import register
from enum import Enum
import numpy as np
import pygame
register(
id='golf-v0',
entry_point='golf_game:GolfEnv', # module_name:class_name
)
class GolfEnv(gym.Env):
metadata = {'render_modes': ['human']}
def __init__(self, render_mode=None, difficulty='Easy'):
self.render_mode = render_mode
self.clock = None
self.fps = 1
self.hole_radius = 25.0 # 1 yard tolerance
self.max_distance = 500
self.start_distance = 400
self.num_strokes = 0
# clubs: mean distance, std deviation
if(difficulty=='Easy'):
self.clubs = {
0: (10, 0), # putter forwards
1: (50, 0), # iron forwards
2: (200, 0), # driver forwards
3: (10, 0), # putter backwards
4: (50, 0), # iron backwards
5: (200, 0) # driver backwards
}
if(difficulty=='Medium'):
self.clubs = {
0: (10, 1), # putter forwards
1: (50, 10), # iron forwards
2: (200, 20), # driver forwards
3: (10, 1), # putter backwards
4: (50, 10), # iron backwards
5: (200, 20) # driver backwards
}
if(difficulty=='Hard'):
self.clubs = {
0: (10, 5), # putter forwards
1: (50, 25), # iron forwards
2: (200, 50), # driver forwards
3: (10, 5), # putter backwards
4: (50, 25), # iron backwards
5: (200, 50) # driver backwards
}
self.action_space = spaces.Discrete(len(self.clubs))
self.observation_space = spaces.Box(
low=0,
high=self.max_distance,
shape=(1,),
dtype=np.float32
)
self.distance = None
# rendering
self.window = None
self.window_size = 800
self.last_action = None
def reset(self, seed=None, options=None):
super().reset(seed=seed)
self.distance = self.start_distance
self.ball_position = self.max_distance - self.distance
self.num_strokes = 0
self.total_reward = 0
observation = np.array([self.distance], dtype=np.float32)
info = {}
return observation, info
def step(self, action):
mean, std = self.clubs[action]
shot = self.np_random.normal(mean, std)
self.last_action = action
if(action < 3):
self.distance -= shot
else:
self.distance += shot
self.ball_position = self.max_distance - self.distance
terminated = abs(self.distance) <= self.hole_radius
truncated = self.num_strokes > 10
if terminated:
reward = 10
elif truncated:
reward = -10000
else:
reward = -abs(self.distance)/100
self.total_reward += reward
observation = np.array([max(self.distance, 0)], dtype=np.float32)
info = {"shot_distance": shot}
self.num_strokes += 1
self.render()
return observation, reward, terminated, truncated, info
def render(self):
if self.render_mode is None:
pass
if self.render_mode == 'human':
if self.window is None:
pygame.init()
self.window = pygame.display.set_mode((self.window_size, 200))
pygame.display.set_caption("Golf RL")
self.clock = pygame.time.Clock()
self.font = pygame.font.SysFont("Arial", 24)
canvas = pygame.Surface((self.window_size, 200))
canvas.fill((34, 139, 34)) # grass
# hole position
hole_x = self.window_size - 50
pygame.draw.circle(canvas, (0, 0, 0), (hole_x, 100), 6)
# convert distance -> screen position
progress = (self.max_distance - self.distance) / self.max_distance
ball_x = int(progress * (self.window_size - 100)) + 50
pygame.draw.circle(canvas, (255, 255, 255), (ball_x, 100), 8)
club_text = self.font.render(f"Club: {self.last_action}", True, (255,255,255))
distance_text = self.font.render(f"Distance: {self.distance:.1f}", True, (255,255,255))
canvas.blit(club_text, (20, 20))
canvas.blit(distance_text, (20, 50))
self.window.blit(canvas, (0, 0))
pygame.display.update()
pygame.display.update()
self.clock.tick(self.fps)
def check_env():
from gymnasium.utils.env_checker import check_env
env = gym.make('golf-v0', render_mode='human')
check_env(env.unwrapped)
def random_rollout():
env = gym.make("golf-v0")
obs, _ = env.reset()
done = False
while not done:
action = env.action_space.sample()
print('Club used: ', action)
obs, reward, terminated, truncated, info = env.step(action)
env.render()
done = terminated or truncated
print(obs, reward)
env.close()
if __name__ == "__main__":
check_env()
random_rollout()
Code
Below is a breakdown of the Deep Q-Learning (DQN) agent designed for the custom Golf-v0 environment. The agent learns to select optimal golf clubs to minimize distance to the hole using experience replay and a neural network approximation of Q-values.
1. Imports and Setup
import gymnasium as gym
import golf_game
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
import random
from collections import deque
import matplotlib.pyplot as plt
import os
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
os.environ["KMP_DUPLICATE_LIB_OK"] = "TRUE"
This section imports required libraries for reinforcement learning, neural networks, and visualization. The code also selects GPU acceleration if available.
2. Replay Memory
class ReplayMemory:
def __init__(self, maxlen):
self.memory = deque(maxlen=maxlen)
def append(self, transition):
self.memory.append(transition)
def sample(self, batch_size):
return random.sample(self.memory, batch_size)
def __len__(self):
return len(self.memory)
This class stores past experiences (state, action, next_state, reward, done). Random sampling from memory helps break correlations between consecutive experiences and stabilizes training.
3. Deep Q-Network (DQN)
class GolfDQN(nn.Module):
def __init__(self, num_inputs, hidden_size, num_actions):
super().__init__()
self.fc1 = nn.Linear(num_inputs, hidden_size)
self.fc2 = nn.Linear(hidden_size, hidden_size)
self.out = nn.Linear(hidden_size, num_actions)
def forward(self, x):
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
return self.out(x)
This neural network approximates the Q-function. It takes the current state (distance to the hole) as input and outputs a Q-value for each possible action (club choice).
4. Agent Initialization
class GolfDQL:
def __init__(self,
hidden_size=128,
learning_rate=0.001,
discount_factor=0.99,
target_sync_freq=500,
replay_memory_size=50000,
batch_size=64):
This defines key hyperparameters for training:
- Learning rate: Controls how quickly the network updates
- Discount factor (γ): Importance of future rewards
- Target sync frequency: How often the target network is updated
- Replay memory size: Maximum stored experiences
- Batch size: Number of samples per training step
5. Optimization Step
def optimize(self, batch, policy_dqn, target_dqn):
states = torch.tensor([s for s, _, _, _, _ in batch], dtype=torch.float32, device=device)
actions = torch.tensor([a for _, a, _, _, _ in batch], dtype=torch.long, device=device)
current_q = policy_dqn(states).gather(1, actions.unsqueeze(1)).squeeze()
This function performs a single gradient update using a batch of experiences. It computes:
- Current Q-values from the policy network
- Target Q-values using the Bellman equation
with torch.no_grad():
max_next_q = target_dqn(next_states).max(1)[0]
target_q = rewards + (1 - dones) * self.gamma * max_next_q
The loss between predicted and target Q-values is minimized using mean squared error, and gradients are applied via backpropagation.
6. Training the Agent
def train(self, episodes, render=False, difficulty='Easy'):
env = gym.make('golf-v0', render_mode='human' if render else None, difficulty=difficulty)
The training loop initializes the environment and neural networks, then runs episodes where the agent interacts with the environment.
if random.random() < epsilon:
action = env.action_space.sample()
else:
action = policy_dqn(state_tensor).argmax().item()
An epsilon-greedy strategy is used to balance exploration and exploitation.
memory.append((state, action, new_state, reward, terminated))
Each transition is stored in replay memory for later training.
if len(memory) > self.batch_size and step_count % 4 == 0:
batch = memory.sample(self.batch_size)
self.optimize(batch, policy_dqn, target_dqn)
The network is periodically trained using sampled batches from memory.
if step_count % self.target_sync_freq == 0:
target_dqn.load_state_dict(policy_dqn.state_dict())
The target network is updated at fixed intervals to stabilize learning.
7. Exploration Strategy
epsilon = max(epsilon - epsilon_decay, epsilon_min)
Epsilon gradually decreases over time, reducing random exploration as the agent learns a better policy.
8. Saving Model and Plotting
torch.save(policy_dqn.state_dict(), "golf_dqn.pt")
The trained model is saved to disk for later use.
moving_avg = np.convolve(rewards_per_episode, np.ones(50)/50, mode='valid')
plt.plot(moving_avg)
A moving average plot of rewards is generated to visualize training progress over time.
9. Testing the Trained Agent
def test(self, episodes, difficulty):
env = gym.make('golf-v0', render_mode='human', difficulty=difficulty)
This function evaluates the trained agent by running it in the environment without exploration.
action = policy_dqn(state_tensor).argmax().item()
The agent always selects the action with the highest predicted Q-value.
10. Running the Agent
if __name__ == "__main__":
golf_agent = GolfDQL()
difficulty = 'Medium'
golf_agent.train(episodes=5000, render=False, difficulty=difficulty)
golf_agent.test(episodes=5, difficulty=difficulty)
The script first trains the agent over many episodes, then evaluates its learned policy in a small number of test episodes.
11. Reinforcement Learning Formulation
- State: Distance to the hole (continuous value)
- Actions: Selection of golf clubs (discrete)
- Reward: Positive for reaching the hole, negative based on distance and penalties
- Policy: Approximated using a neural network (DQN)
This implementation demonstrates how Deep Q-Learning can be applied to a simple continuous-state environment with discrete actions.
Full Code
Full implementation of the DQN agent for the Golf-v0 environment:
import gymnasium as gym
import golf_game
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
import random
from collections import deque
import matplotlib.pyplot as plt
import os
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
os.environ["KMP_DUPLICATE_LIB_OK"] = "TRUE"
# --- Replay Memory ---
class ReplayMemory:
def __init__(self, maxlen):
self.memory = deque(maxlen=maxlen)
def append(self, transition):
self.memory.append(transition)
def sample(self, batch_size):
return random.sample(self.memory, batch_size)
def __len__(self):
return len(self.memory)
# --- DQN Network ---
class GolfDQN(nn.Module):
def __init__(self, num_inputs, hidden_size, num_actions):
super().__init__()
self.fc1 = nn.Linear(num_inputs, hidden_size)
self.fc2 = nn.Linear(hidden_size, hidden_size)
self.out = nn.Linear(hidden_size, num_actions)
def forward(self, x):
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
return self.out(x)
# --- DQN Agent ---
class GolfDQL:
def __init__(self,
hidden_size=128,
learning_rate=0.001,
discount_factor=0.99,
target_sync_freq=500,
replay_memory_size=50000,
batch_size=64):
self.hidden_size = hidden_size
self.lr = learning_rate
self.gamma = discount_factor
self.target_sync_freq = target_sync_freq
self.memory_size = replay_memory_size
self.batch_size = batch_size
self.loss_fn = nn.MSELoss()
self.optimizer = None
def optimize(self, batch, policy_dqn, target_dqn):
states = torch.tensor([s for s, _, _, _, _ in batch], dtype=torch.float32, device=device)
actions = torch.tensor([a for _, a, _, _, _ in batch], dtype=torch.long, device=device)
next_states = torch.tensor([ns for _, _, ns, _, _ in batch], dtype=torch.float32, device=device)
rewards = torch.tensor([r for _, _, _, r, _ in batch], dtype=torch.float32, device=device)
dones = torch.tensor([d for _, _, _, _, d in batch], dtype=torch.float32, device=device)
current_q = policy_dqn(states).gather(1, actions.unsqueeze(1)).squeeze()
with torch.no_grad():
max_next_q = target_dqn(next_states).max(1)[0]
target_q = rewards + (1 - dones) * self.gamma * max_next_q
loss = self.loss_fn(current_q, target_q)
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
def train(self, episodes, render=False, difficulty='Easy'):
env = gym.make('golf-v0', render_mode='human' if render else None, difficulty=difficulty)
num_states = env.observation_space.shape[0]
num_actions = env.action_space.n
epsilon = 1.0
epsilon_decay = 1 / episodes
epsilon_min = 0.05
memory = ReplayMemory(self.memory_size)
policy_dqn = GolfDQN(num_states, self.hidden_size, num_actions).to(device)
target_dqn = GolfDQN(num_states, self.hidden_size, num_actions).to(device)
target_dqn.load_state_dict(policy_dqn.state_dict())
self.optimizer = torch.optim.Adam(policy_dqn.parameters(), lr=self.lr)
rewards_per_episode = np.zeros(episodes)
step_count = 0
for episode in range(episodes):
state, _ = env.reset()
state = np.array(state, dtype=np.float32)
terminated = False
truncated = False
episode_reward = 0
num_strokes = 0
while not terminated and not truncated:
if random.random() < epsilon:
action = env.action_space.sample()
else:
with torch.no_grad():
state_tensor = torch.tensor(state, dtype=torch.float32, device=device)
action = policy_dqn(state_tensor).argmax().item()
new_state, reward, terminated, truncated, _ = env.step(action)
new_state = np.array(new_state, dtype=np.float32)
memory.append((state, action, new_state, reward, terminated))
state = new_state
episode_reward += reward
step_count += 1
num_strokes += 1
if len(memory) > self.batch_size and step_count % 4 == 0:
batch = memory.sample(self.batch_size)
self.optimize(batch, policy_dqn, target_dqn)
if step_count % self.target_sync_freq == 0:
target_dqn.load_state_dict(policy_dqn.state_dict())
rewards_per_episode[episode] = episode_reward
epsilon = max(epsilon - epsilon_decay, epsilon_min)
if(episode % 50 == 0):
print(f"Episode {episode} | Reward: {episode_reward} | Strokes: {num_strokes} | Epsilon: {epsilon:.3f}")
torch.save(policy_dqn.state_dict(), "golf_dqn.pt")
env.close()
# --- Plot moving average ---
plt.figure(figsize=(10,5))
moving_avg = np.convolve(rewards_per_episode, np.ones(50)/50, mode='valid')
plt.plot(moving_avg)
plt.title("Moving Average Reward (50 episodes)")
plt.xlabel("Episode")
plt.ylabel("Reward")
plt.savefig("golf_dqn_training.png")
plt.show()
def test(self, episodes, difficulty):
env = gym.make('golf-v0', render_mode='human', difficulty=difficulty)
num_states = env.observation_space.shape[0]
num_actions = env.action_space.n
policy_dqn = GolfDQN(num_states, self.hidden_size, num_actions).to(device)
policy_dqn.load_state_dict(torch.load("golf_dqn.pt", map_location=device))
policy_dqn.eval()
for episode in range(episodes):
state, _ = env.reset()
state = np.array(state, dtype=np.float32)
terminated = False
truncated = False
episode_reward = 0
while not terminated and not truncated:
with torch.no_grad():
state_tensor = torch.tensor(state, dtype=torch.float32, device=device)
action = policy_dqn(state_tensor).argmax().item()
state, reward, terminated, truncated, _ = env.step(action)
episode_reward += reward
print(reward)
print(f"Episode {episode} | Reward: {episode_reward}")
env.close()
if __name__ == "__main__":
golf_agent = GolfDQL()
difficulty = 'Medium'
golf_agent.train(episodes=5000, render=False, difficulty=difficulty)
golf_agent.test(episodes=5, difficulty=difficulty)
Results
This section presents the training results for the Golf-v0 Deep Q-Learning agent across three difficulty settings: Easy, Medium, and Hard. Each plot shows the moving average reward (50 episodes), which helps visualize learning progress over time.
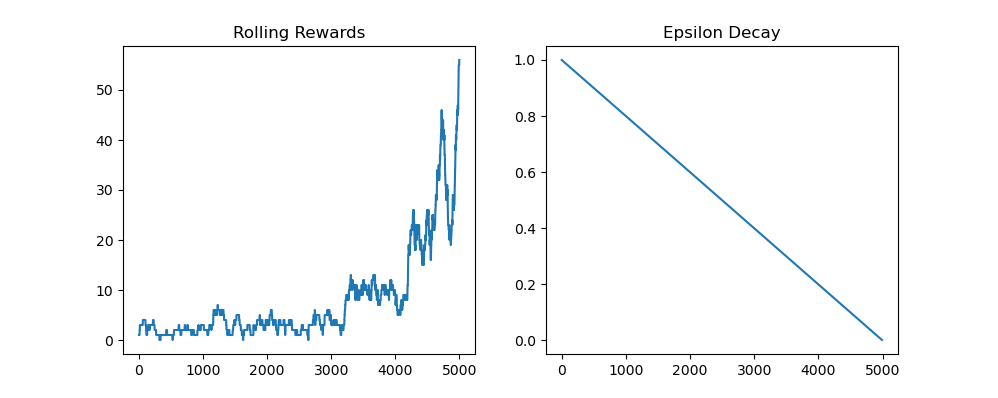
1. Easy Difficulty
In the Easy setting, all golf shots are deterministic (no randomness). This allows the agent to learn a stable and predictable policy.
- The reward steadily improves over time
- Convergence is relatively fast compared to other settings
- The agent learns consistent club selection for minimizing distance
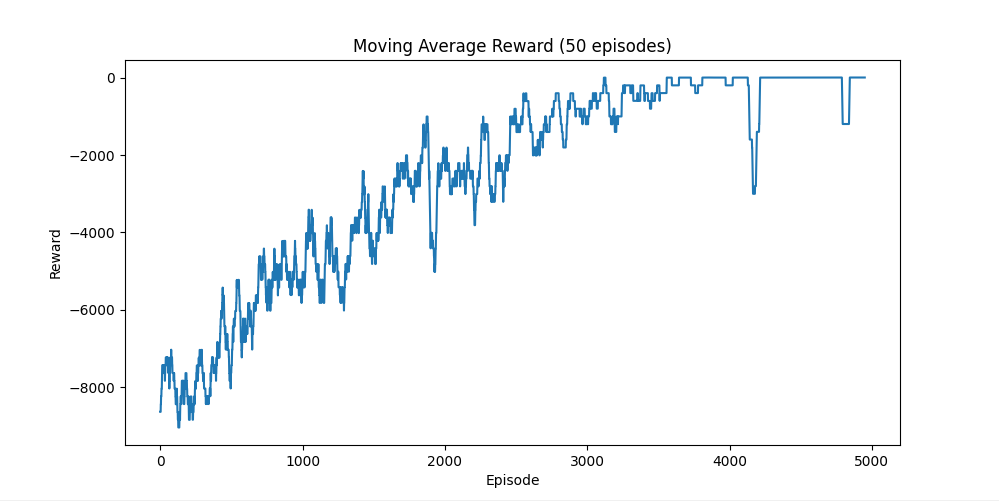
2. Medium Difficulty
In the Medium setting, moderate randomness is introduced into shot distances. This increases uncertainty and makes learning more challenging.
- Rewards improve more gradually compared to Easy
- Noticeable fluctuations due to stochastic outcomes
- The agent still learns a generally effective strategy
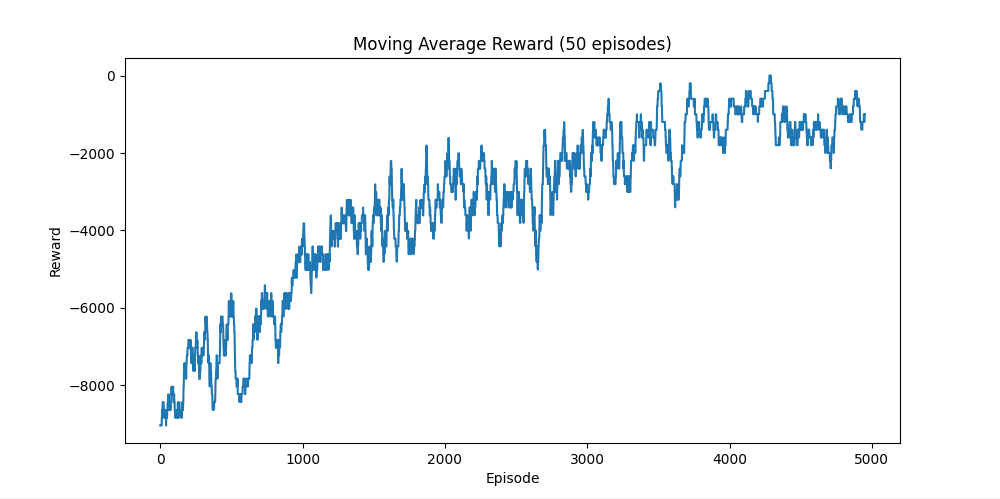
3. Hard Difficulty
The Hard setting introduces significant randomness in shot distances, making precise control difficult.
- Learning is slower and less stable
- High variance in rewards due to unpredictable outcomes
- The agent still improves but does not converge as cleanly
4. Reward Function Design
The reward function went through several iterations to achieve stable learning:
- Initial approach:
A simple reward of
-1 per strokeand+10for reaching the hole.
This approach failed because the agent did not learn meaningful distance-based behavior and lacked guidance toward the goal. - Second attempt:
A truncation penalty of
-10000after exceeding the stroke limit.
This caused unintended behavior where the agent would continue taking random actions until termination, rather than learning efficient play. - Final reward design:
- Reward =
-|distance_to_hole| / 100for each step +10for reaching the goal region- Large penalty for exceeding maximum strokes
- Reward =
This final design provides dense feedback, allowing the agent to continuously evaluate whether its actions are improving its position. As a result:
- The agent learns to minimize distance rather than just survive
- Training becomes more stable and consistent
- The policy generalizes better under stochastic conditions
Additionally, instead of requiring the ball to land exactly in the hole, a tolerance radius was introduced. This accounts for randomness in shot distances and makes the task more achievable, especially in Medium and Hard difficulties.
Dynamic Resource Allocation
Environment
This experiment explores dynamic resource allocation in a multi-beam satellite system using deep reinforcement learning (DRL). The agent interacts continuously with the environment to allocate satellite resources such as channels, power, and traffic to user requests while maximizing long-term system performance.
DDRA Architecture
The Deep Dynamic Resource Allocation (DDRA) approach allows the satellite agent to select actions based on current states and rewards. The agent observes the current system state and global feedback, chooses actions via a Q-network, and stores experience tuples
(st, at, rt, st+1) in a replay memory. Mini-batches are sampled from memory to update the Q-network using a target network, and the target network is periodically updated to stabilize learning.
MDP Model
The resource allocation task is formulated as a Markov Decision Process (MDP) consisting of:
- States (st): Include the currently allocated power and rate across beams, and the incoming user request
ut = [Qt, µt, bt](traffic volume, service duration, and user beam location). Formally:st = [Pt, Vt, ut]. - Actions (at): Decisions for allocating resources to a new user, including channel assignment
ct, traffic allocationvt, and optional traffic reductiondtfor existing users:at = [ct, vt, dt]. This breaks a complex decision into sequential discrete choices. - Rewards (rt): Multi-component reward function:
- If a request is blocked due to lack of resources:
rt = Rblocked < 0. - If a request is accepted:
rt = w · (vt / Qt), wherevtis allocated traffic,Qtis requested traffic, andwis a positive scaling factor.
- If a request is blocked due to lack of resources:
Learning Framework
- DRL agent uses a Deep Q-Network (DQN) to approximate the action-value function in high-dimensional spaces.
- Experience replay stores transitions for stable training; the target network improves convergence.
- Action selection uses an ε-greedy policy with decaying exploration:
ε = εmin + (ε0 − εmin) e^(−t / decay).
This environment models sequential decision-making in a stochastic satellite network, where the agent adapts allocations dynamically to optimize long-term resource utilization and service quality.
Reference: A Deep Reinforcement Learning Based Dynamic Resource Allocation Approach in Satellite Systems, IEEE, 2025. IEEE Xplore
Code
As of right now, this project is still in the research phase and there is no code for it
Code
As of right now, this project is still in the research phase and there is no code for it
Results
As of right now, this project is still in the research phase and there are no results